
Part 3
By Juan B. Plaza and Giulio Maffini
Now that we have explored what AI can do for GIS in the first two parts of this series, let’s embark in the more complex task of exploring what a GIS-empowered AI will look like.
First, let us clarify that it is our belief that it would be naïve to assume that a fully autonomous AI engine will address the issue of representing the Earth the same way humans have done for millennia. For starters, we have been “prisoners of cartography” since the first maps were chiselled on a rock wall, pressed on a clay tablet, or scribbled on papyrus.
AI will not have the limitation of representing a round surface in a 2D format for convenience. AI will always “think” and analyze on a spherical surface and will present its results in any way we want, but the default way to show results will be over a round representation of our reality, which is the way it exists.
We will explore some scenarios of embedding GIS knowledge in an AI application that thinks spatially. This is not about AI using any particular GIS software application it is about AI being trained, like a spatial data scientist to “gather knowledge about the world and organizing and condensing that knowledge into testable laws and theories,” as E.O. Wilson wrote in his book, Consilience.
To become a spatial thinking scientist, the AI application must be able to find and access relevant spatial data to the domain of enquiry and have knowledge of generic geospatial-mathematical algorithms underpinning any GIS functionality. This material is scientific knowledge largely accessible to the public. This AI would understand what questions are asked and create spatial models of the real world to answer them using geographical expertise. There is a possibility that AI, with this training, could invent from scratch new methods of spatial analysis that humans have not thought of.
Since, as far as we know, no such AI application exists, we can use a thought experiment for logical thinking to speculate and change paradigms on what capabilities it might have and how it would perform them.
Let’s start with a simple commercial example that requires no private data at all. You are a provider of solar panel solutions, including power walls, and want to fine-tune your target audience for marketing and to increase sales and you have access to a cloud-based AI app. You know nothing about GIS. You have only provided the AI app with a few photos showing what solar panels look like from above. You explain that they are installed on roofs of houses in a particular orientation to the sun. You also tell the app that people within a certain socio-economic range purchase solar panels. Your ask the AI app for advice on where to target your sales and marketing.
The AI uses what you have given it and selects three spatial data layers from its library:
– A street and address database (OpenStreetMap – coverage worldwide)
– Basic socio-economic census data for each address (U.S. Census Bureau)
– Air photos and satellite imagery (many free satellite imagery data sources)
Using the provided photos of solar panels, the AI app performs a quick scan of some air photos for the market area to detect roofs with suspected solar panels. At this point, it might get back to you and ask you to confirm if it has correctly identified solar panels. (This verification process is the machine learning training). Once the AI app has reached a sufficiently accurate detection level it stops and proceeds with the next stage in the analysis.
First- and second-level triangular divisions in a QTM.
The AI app now scans the whole target region. When it detects a solar panel, the AI app creates a record and assigns the record to the nearest street address. Using the address, the AI app queries the U.S. Census Bureau data and assigns a socio-economic profile to each tagged address record in the database. The AI app has also been told that that the likelihood of installing solar panels is influenced by how many other homes in the

Decreasing size and increasing Accuracy in a QTM. Images Courtesy of Zheng Wang , Xuesheng Zhao , Wenbin Sun, Fuli Luo, Yalu Li and Yuanzheng Duan.
immediate neighborhood have solar panels. So, for each address the AI app calculates how many solar panels there are in several distance bands—¼ mile, ½ mile, and one mile—around each address.
Armed with this knowledge for all the addresses in the database, the AI app now builds a probability model of a solar panel presence/non-presence and identifies all the addresses that have all the right conditions for solar panels, but currently do not have them. You get a list of addresses, each tagged with a probability score, for which you can then create a marketing campaign.
The target marketing may need get a little more sophistication for the power wall target marketing and sales. Power walls are inside houses. Instead of selling electricity back to the grid, power walls store electricity from the solar panels in the home. They can supply the home for a few days of normal electricity use. You cannot use the same type of analysis to train the AI app to target them. You have told the AI app that power outages are due to a variety of factors, including increasing severe weather events. The AI now adds two more spatial datasets to its analysis:
Frequency and location of severe weather events (NOAA) in the target region
Frequency of power outages (utility companies)
The AI app now has added knowledge to target those addresses that have high potential for solar panels and additional reasons to install a power wall.
With this new data, the AI app can quickly modify its training to target marketing and sales of other devices, such as generators, by adding to the address records which addresses have access to piped natural gas service. The new AI app can be trained to identify generators (that are always outside) and calculate different probability profiles of socio-economic conditions while excluding homes with solar panels.
The geographic extent of such an AI application can cover a city, a state, the entire U.S., or the world. The purpose of the AI application may also change from selling things to identifying addresses eligible for climate adaptation programs and incentives.
These kind of generic spatial problems “use what I told you about, something I am looking for, and tell me where to find more” occur across a wide range of disciplines from mineral and metals exploration, epidemiology to criminal investigations. They can employ a handful of spatial data layers or hundreds.
An AI app that thinks spatially needs to understand the domain of the query. Ideally, the library of AI spatial data used to train and search to respond to questions should be accessible, without performing laborious map projection transformations on the fly. Today, GIS data is in many vendor-specific formats and many, many projection systems. We have to remind ourselves that maps are just reports of the spatial data.
Storing the GIS spatial data in a projection system is traditional for humans, but it is not required for an AI app to build a spatial database. Spatial data stored in map formats and projections is just an artificial restriction or limitation, that, like us, turns the technology into another prisoner of cartography. The AI spatial data needs to be set free from maps and cartographic projections.
A great deal of GIS spatial data is in vector format. Vector format is good for representing spatial data representing topological relationships of networks, such as rivers and streams, roads, rail, electrical, and telecom networks. Vector format is also good for well-defined objects, such as precise property parcels surveys. Most of all, it is superb for making beautiful cartographic maps. But it is not a good format for representing poorly defined areas, such as forests, wetlands, and other forms of natural land cover that have inherently fuzzy-edge conditions between one area to another.
The very precise vector representation of XYZ coordinates in these cases is misleading. It does not reflect the vagueness and ambiguity encountered during the digitizing of the vectors. There are two types of uncertainties—spatial accuracy, and the attribute accuracy. An AI application with the knowledge of how the spatial data was captured and therefore its accuracy needs to be integrated in its spatial data model.
There is a lot of GIS knowledge about the difference between spatial accuracy and precision, but we humans have not done a good job of systematically applying this knowledge in how we structure spatial data in GIS. Usually, we just provide statistical error summaries. The AI app also needs to understand the difference between precision and accuracy and embed this knowledge in structure of the spatial data it uses for training and searching.
 What other spatial structures are out there that can do all this for AI? Well, there is raster format (used to store data collected by air photos and satellite imagery) but rectilinear cells are poor for representing in a consistent area and projection a spherical surface like the earth. Raster formats also have a tendency create massive data records, and they have many potential resolutions.
What other spatial structures are out there that can do all this for AI? Well, there is raster format (used to store data collected by air photos and satellite imagery) but rectilinear cells are poor for representing in a consistent area and projection a spherical surface like the earth. Raster formats also have a tendency create massive data records, and they have many potential resolutions.
There is another option: a Geodesic Planetary Model using a Quaternary Triangular Mesh (QTM) first developed by Geoffrey Dutton, where any location on a planet has a hierarchical address, or geocode, which it shares with all other locations lying within the same facet. As depth in the tree increases, facets grow smaller, geocodes grow longer and tend to become more unique, being shared by fewer entities.
As is shown in Table 1, triangular subdivision tiling can cover the earth with a triangular mesh of potentially great precision to accommodate even the most precise surveying methods.
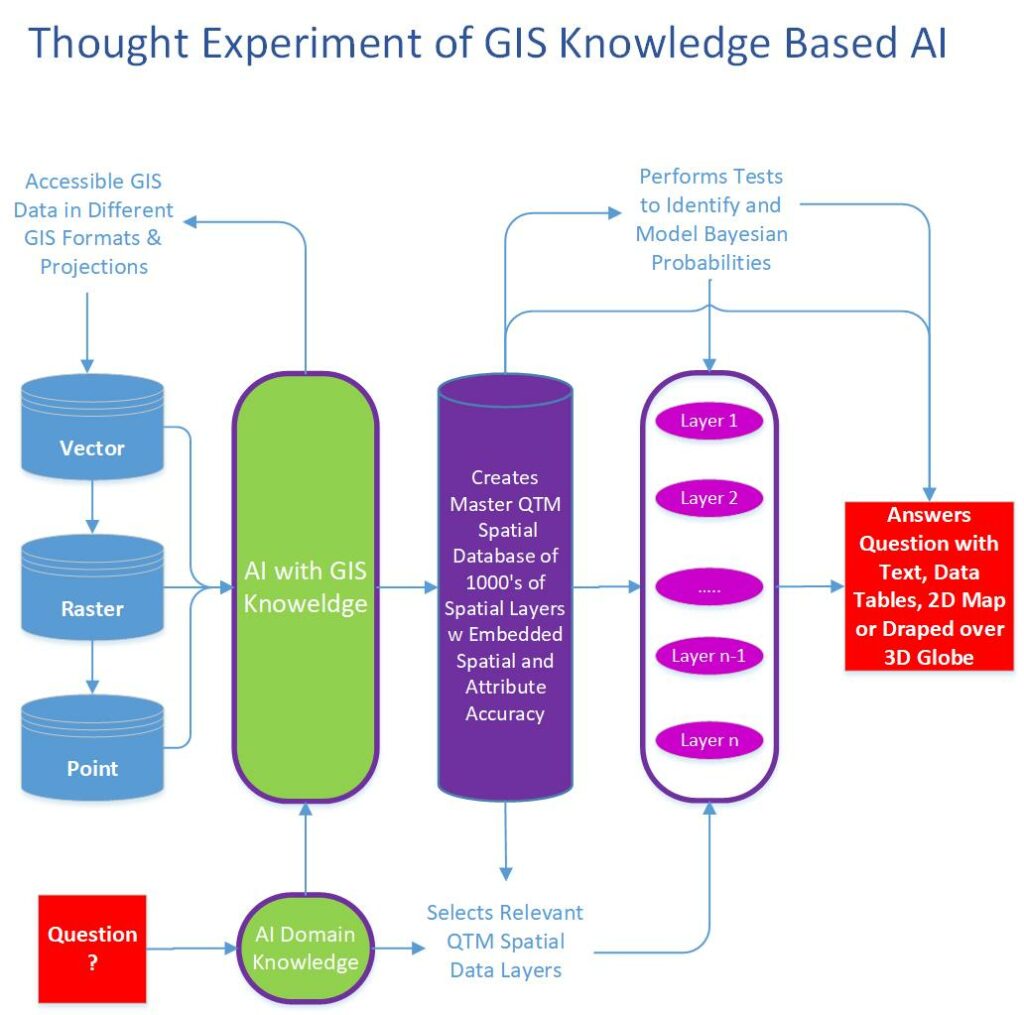
Our human-built GIS and spatial data based on a map paradigm is too cumbersome and inefficient. The diagram titled Thought Experiment of GIS Knowledge Based AI attempts to show at a high-level how GIS knowledgeable AI might function.
What conclusions can we draw from our thought experiment?
The first is that AI will not replicate our GIS software and cartographic data structures to store and analyze spatial data. Converting our existing legacy spatial data layers to something like the Quaternary Triangular Mesh (QTM) structure will enable AI to integrate hundreds and even thousands of spatial data layers in a consistent spatial data format with built-in varying spatial and attribute accuracy.
Second, AI will likely reinvent GIS functionality based on data processing of hierarchical address, or geocoded data trees. This will create new algorithms for building, testing, and statistically validating spatial models of discovery.
Third, AI will answer our questions with text, data tables, and beautifully rendered 2D cartographic map products in any projection or cartographic style we desire. Alternatively, it will present the map results draped over a virtual 3D globe (Google Earth). However, these great visual displays will just be reports for the consumption and appreciation of humans of the spatial data, not the data itself.
Finally, and more consequential to our profession, AI will break free of the cartography paradigm prison by embracing the spherical nature of our world and representing all its findings to our queries in any format we want, but rest assured that all the analyses and the underlying data will be in a global structure and not a 2D adaptation.
In order to test our hypothesis, we went back to ChatGPT 3.5 and subjected our Thought Experiment to the current state of AI and the results will surprise you the same way it surprised us. In short, today AI is aware of QTM and how to actually make this paradigm shift possible. The entire conversation with ChatGPT can be found here. 
Giulio Maffini started his career in the 70s as an urban and regional planner. Later he founded a company (TYDAC) to build Spatial Analysis PC desktop software (SPANS). In the early 90s he was part of team that commercialized an all-relational, multi user, Oracle-based enterprise GIS (VISION*) for Utilities, Telecom’s, and Municipalities. He is now an advisor to spatial technology companies. Juan B. Plaza is the CEO of Plaza Aerospace, a drone and general aviation consultant firm that specializes in modern uses for manned and unmanned aviation in the areas of mapping, lidar, and precision GNSS.