Up to now I have talked about a least squares adjustment as if everyone knows what it involves. In this article, I discuss what a least squares adjustment is and what makes it so valuable in adjusting observational data.
Note: Please click on the images below to see them or read our full issue to check the correct math configurations.
-

- o2

-

- ·wv2

-

- LIJ

Least squares adjustments have their roots in the normal distribution, which is pictured in Figure 1. The equation for the normal distribution curve is Equation (1) where:
- v represents the residual of the observations and is plotted on the x axis,
- y the probability of the residual occurring
- o2 the variance of the observations, and
- e the exponential number, which is the transcendental number 2.718281828….
To maximize the probability of this function, the sum of the weighted, squared residuals (·wv2) must be minimized.

This process can be done by writing equations for every observation in terms of their unknown parameters. For a horizontal survey this would mean a system of equations representing the angles, azimuths, and distances, which are written in terms of their unknown station coordinates (n, e).
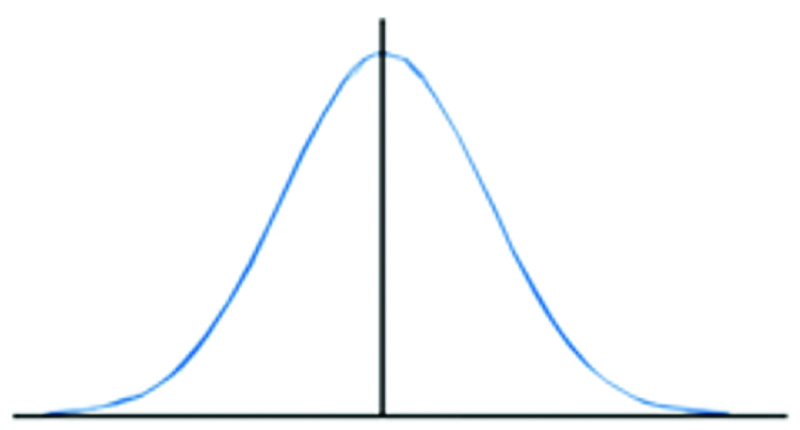
Figure 1: normal distribution curve
However, each of these equations is nonlinear. To solve a system of nonlinear equations, they must first be linearized using a first-order Taylor series expansion. For example, the familiar nonlinear distance equation with its residual is Equation (2) where (n, e) are the northing and easting coordinates of the endpoint stations i and j for the distance observation lij with a residual error of vl.
The linearized equation for the distance equation is Equation (3) where:
(dn, de) are corrections to approximate values for the unknown parameters (n, e),
zero subscripts indicate values determined using the approximate coordinate values,
K is the difference between the observed and computed length of the distance where the computed length IJ is determined from the approximate coordinate values, and
v is the residual error.
In the solution of these equations, the residual v is dropped, and the solution is iterated applying the corrections dn and de to the approximate unknown parameters n and e until the corrections to the corrected coordinates become negligibly small (in essence, until the coordinate values for the stations are resolved to less than the accuracy of the survey, which is typically less than 0.005 ft or 0.0005 mm). Linearized equations are written similarly for the azimuth and angle observations.
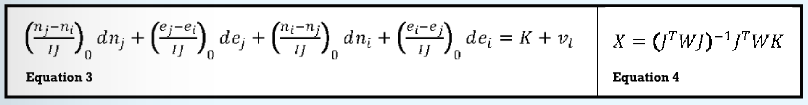
Performing the Adjustment
To minimize the sum of the weighted, squared residuals, that is, to perform a least squares adjustment, all of the observation equations are written in matrix form. However, as we all know from our Algebra I class in high school, they could be solved by hand if it weren’t so time-consuming and hard. Thus, it was the availability of computers and their ability to be programmed to solve large systems of equations that made the least squares process available to us.
(The derivation and application of the least squares method occurred at the end of the 18th century and is attributed to Karl Gauss while he was a graduate student. Thus the method has been available a long time, but it wasn’t until the advent of the micro-computer that it became available to most surveyors.)
By forming the matrices as shown in Equation (4) and then solving this system of equations, the resultant solution yields the minimized sum of the squared residuals. This statement is shown in my book Adjustment Computations: Spatial Data Analysis.
In Equation (4):
the J is a matrix of coefficients determined from the linearized equations; that is for a distance, it is the parenthetical values in Equation (3) evaluated at some approximate coordinate values for the stations I and J;
W a matrix of weights for each observation;
K a vector of the differences between the observed and computed values for each measurement; and
X a matrix of corrections to be applied to the approximate coordinates for the stations. Because in a horizontal adjustment the equations are nonlinear, this solution process must be iterated until the corrections to the approximate coordinates become negligibly small. This is also true for a geodetic adjustment. However, the equations for a differential leveling network and a GNSS baseline vector adjustment are linear and thus can be solved without iterating.
So What Is the Least Squares Method?
It is simply a method where equations are written for each observation in terms of the unknown parameters. These equations are weighted according to the precisions of the observations in order to return the errors back to their sources.
The weighted equations are then solved using Equation (4), which minimizes the sum of the weighted, squared residuals and yields the most probable solution for any set of data. It is a method of solving an over-determined system of equations that yields the most probable values for the unknown parameters. During this process all geometric constraints are satisfied.
In essence, the least squares method is nothing more than what many of us did in an algebra class when the instructor asked us to solve a system of equations for the unknown parameters x and y. Back then, we solved these equations by the process of elimination.
The least squares method will yield the most-probable solution for any given set of data.
However, for each station, we have two unknown x and y‘s. For a survey with 10 stations, we could have 20 unknowns. Thus, the process would be difficult to perform by hand as we did in algebra class, but the fact that we use matrices and computers does not make it any more foreign than using some other method such as the compass-rule adjustment.
It is simply a process of solving a system of equations for unknown parameters. This process results in a minimum for the sum of the weighted, squared residuals when we follow Equation (4) and the most probable solution for the given set of data.
The least squares method does not guarantee that the solution is always a good one. Just like other methods of adjustment, the basic principle of garbage in, garbage out still applies. However, if care is taken in collecting our observations and all systematic errors are removed from the observations, it will always yield the most-probable solution for any given set of data.
It additionally provides post-adjustment statistics such as standard deviations on the adjusted coordinates and observations, as well as error ellipses for the stations that allow the user to analyze the results and determine if the results are within the tolerances of the project.
It also provides advanced statistical methods that allow the user to analyze the observations for blunders, but that is for my next series of articles. Until then, happy surveying.