As the volume, velocity, and variety of the data generated to address worldwide geospatial needs has steadily grown, advances in the systems and algorithms needed to produce spatial and temporal resolution data have not kept pace. This disparity has suppressed expected industry advancements and created an urgent need to explore and adopt innovative technologies that can support the expanding and essential production of geospatial data.
![]() Enter deep learning. Deep learning is a machine learning technique that seeks to teach computers to learn by example. In the field of artificial intelligence, deep learning refers to a class of artificial neural networks whose architectures contain multiple hidden layers, which learn from different features at multiple levels of abstraction.
Enter deep learning. Deep learning is a machine learning technique that seeks to teach computers to learn by example. In the field of artificial intelligence, deep learning refers to a class of artificial neural networks whose architectures contain multiple hidden layers, which learn from different features at multiple levels of abstraction.
In the field of remote sensing, deep learning algorithms seek to teach computer systems to exploit the unknown structure within the input distribution to discover good representations, often at multiple levels, of the features it needs to extract from the data. This frees the geospatial specialist from manually extracting requested project features and writing code, enabling the specialist to design the framework that will continue to create a pipeline of problems and solutions to increase the computer’s capabilities and enable it to be ready for the next project.
As a result, deep learning is helping the geospatial industry address the diversity and deluge of data by making the production process more efficient and effective.
“It historically takes five to six times longer with the traditional remote sensing method and the quality is about half of what deep learning can do in that time,” Woolpert vice president and market director Brian Stevens said. “We used to achieve between 30 percent to 45 percent accuracy using traditional extraction methods, and now we’re seeing an improvement ranging from 70 percent to 80 percent. The footprints are coming out very nice and clean. Deep learning shortens production time, while doubling accuracy. This is an exciting technology, which as it evolves will have a huge impact on the GIS community.”
Those who are utilizing remote-sensing data generated by deep-learning techniques confirm that the process is providing value specific to their geospatial needs.
“Improving the efficiency and reliability of our geographic information system (GIS) products and services continues to be a top priority,” Franklin County (Ohio) auditor Michael Stinziano said. “By utilizing innovative techniques such as deep learning, the office can produce more precise geospatial data that enhance our appraisal processes while providing higher-quality mapping services to the businesses and residents of Franklin County.”
Growth in Remote Sensing Data Needs
Remote sensing is the process of converting data into information through analysis and feature extraction. The technology is used to acquire information about the earth’s surface to analyze its physical characteristics, generating maps and GIS data for a plethora of expanding applications around the world.
 According to Market Watch, the global remote sensing services market is estimated to have a compound annual growth rate of 14.9 percent between 2017 and 2025, when it will reach an estimated value of $32.8 billion. The market is driven by a rising need for remote sensing services in: mapping, coastal analysis and navigation; military, defense, and homeland security; precision agriculture; mineral exploration, pipeline monitoring, and impervious surface mapping; disaster assessment, mitigation, and management; and a host of economic and infrastructure applications. In addition, the growth in the capabilities of cloud computing is expected to create new avenues for the market in the coming years.
According to Market Watch, the global remote sensing services market is estimated to have a compound annual growth rate of 14.9 percent between 2017 and 2025, when it will reach an estimated value of $32.8 billion. The market is driven by a rising need for remote sensing services in: mapping, coastal analysis and navigation; military, defense, and homeland security; precision agriculture; mineral exploration, pipeline monitoring, and impervious surface mapping; disaster assessment, mitigation, and management; and a host of economic and infrastructure applications. In addition, the growth in the capabilities of cloud computing is expected to create new avenues for the market in the coming years.
Traditionally, geospatial professionals have gained domain expertise through school and/or work experience to acquire and advance the knowledge needed to perform the work required. Key aspects of academic and on-the-job education for remote sensing have involved learning the rules of detecting and monitoring the physical characteristics of an area using remotely collected data and imagery, developing algorithms appropriate to that project, and writing software applications to accurately map that area and solve problems.
The introduction of deep learning has flipped the script. Geospatial specialists are teaching the computer the rules of remote sensing and training it to develop algorithms and write software. This training involves feeding the computer examples of previous problems encountered, as well as the solutions to solve those problems. This process is performed many times until the computer learns to identify patterns and can extract a characteristic, or a mathematic variable, to write the software itself.
Developing these systems that can learn from previous project experience and that have the capability to interpret the requirements of a question or request, analyze the available data, and provide an answer is enabling firms to keep pace with myriad data requests and to continually advance the product and the industry.
Around 2018, Woolpert pivoted from solely employing traditional remote sensing processes and began to investigate and integrate the deep-learning method. After realizing the need that it fills and the immense value that this method can provide, the firm made additional investments in research, development, and training.
Woolpert’s primary focus for deep learning as it applies to remote sensing has been in developing processes and solutions to generate three products from this technique: building footprints, impervious surfaces, and elevation-derived hydrography (EDH) datasets. These deliverables were selected due to the volume of training material available, the multiple requests to support this type of project, and the far-reaching benefits of producing data for these initiatives.
“We perform multiple building footprint and impervious surface data collections each year, so we have very accurate building training data accrued from the various geographies across the U.S.,” Stevens said. “For EDH, we want to develop that pipeline to be able to support the U.S. Geological Survey’s mission to map the hydrographic features covering the entire United States in support of its 3D Elevation Program. These datasets are vital to addressing flooding, erosion, sedimentation, and other threats to our ecosystem, environment, and infrastructure.”
How Deep Learning for Remote Sensing Works
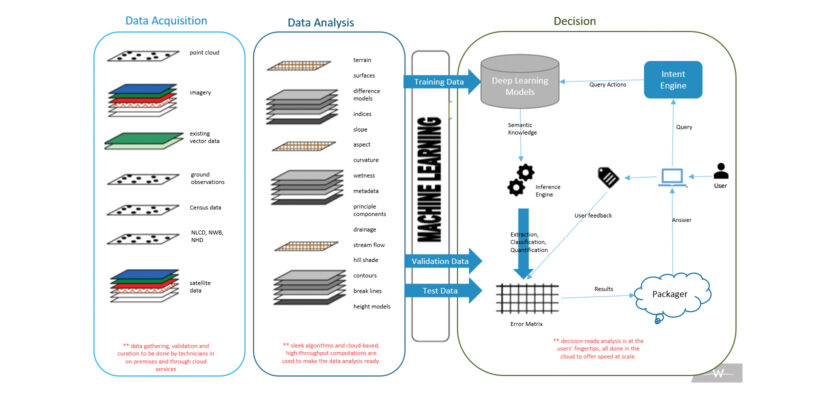
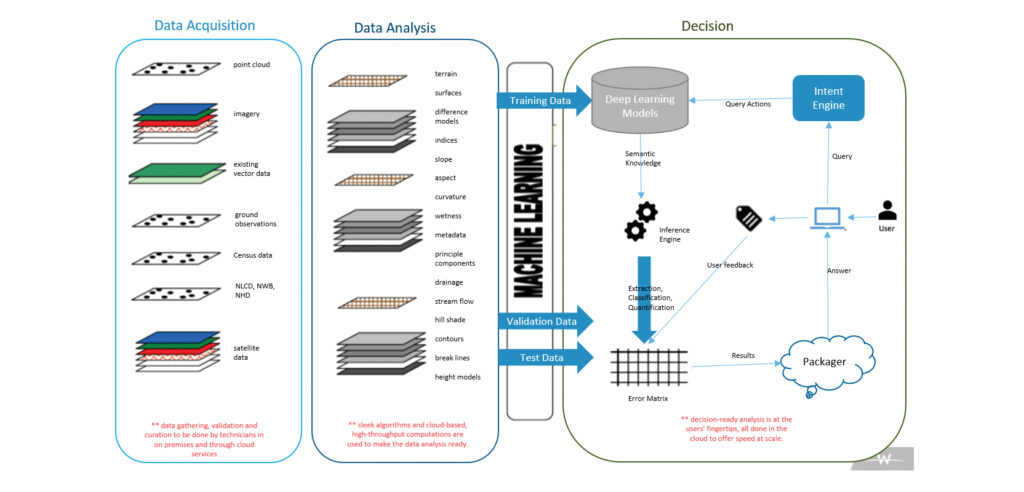
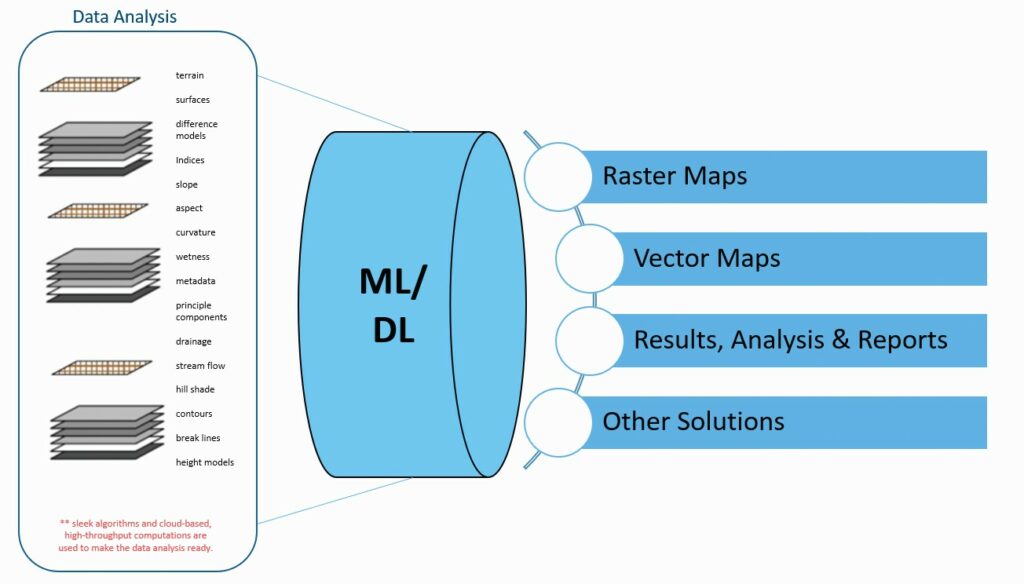
The aim of deep learning for remote sensing is to use science-based methods to create decision-ready analysis. This involves gathering and preparing data—raster, point cloud, vector, field observations, etc.—and analyzing data from surfaces, principle components, band ratios, band indices, statistical models, metadata, etc., to provide decision-ready analysis that includes impervious, occlusion, and encroachment data.
There are multiple methods for feature extraction and mapping in remote sensing, including manual 2D and 3D mapping, supervised image classification, unsupervised image classification, and GEOBIA, or geographic object-based image analysis. Each method has inherent advantages and constraints, and each creates varying demands for research and algorithm development.
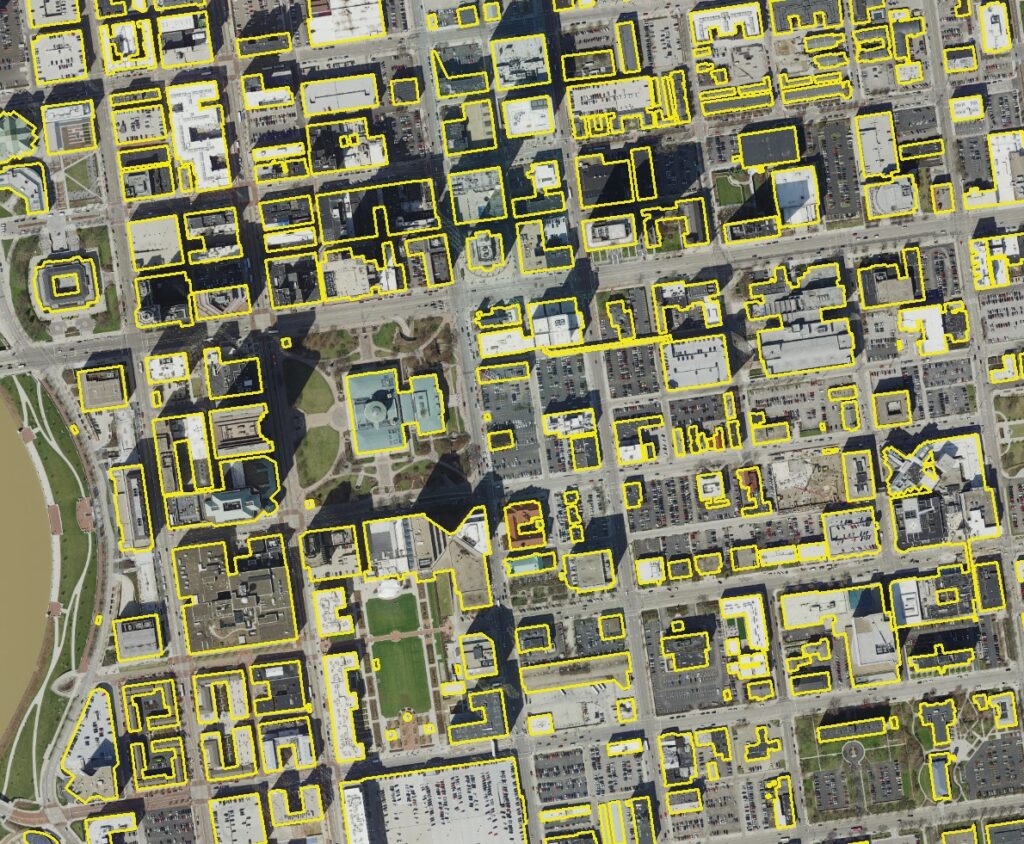
This image of downtown Columbus, Ohio, illustrates the building features extracted by the computer using deep learning techniques for remote sensing. Courtesy of Franklin County.
Ten to 15 years ago, imagery was the primary source of remote sensing data, while today many additional datasets have been incorporated within the feature extraction process, including synthetic aperture radar, bathymetry, mining analysis, lidar, thermal imagery, line scanning with unmanned aircraft systems, etc., as inputs of the mapping process.
Still more source datasets are being developed, making it more crucial that a highly-skilled technical person with domain expertise is part of the feature extraction process. This aspect of traditional remote sensing has often hindered its widespread use as a problem-solving tool for most business and government agencies.
 Deep learning is valuable because it can bridge that knowledge gap to provide the benefits of remote sensing even when a domain expert is not readily available, especially when high-quality mapping data or labeled data, exists. The traditional approach to processing remote sensing data still demands appropriate mapping methods specific to each project; matching the scanned or vector data with mapping data obtained via satellite, aerial imagery or lidar; and analyzing that data to extract features requested by the client. The process just requires less human bandwidth to perform.
Deep learning is valuable because it can bridge that knowledge gap to provide the benefits of remote sensing even when a domain expert is not readily available, especially when high-quality mapping data or labeled data, exists. The traditional approach to processing remote sensing data still demands appropriate mapping methods specific to each project; matching the scanned or vector data with mapping data obtained via satellite, aerial imagery or lidar; and analyzing that data to extract features requested by the client. The process just requires less human bandwidth to perform.
Deep learning enables the input of raw data—pixels in case of image data or points in the case of lidar—into the learning algorithm without first extracting features or defining a feature vector. Deep-learning algorithms can learn the correct set of features and can do this more adeptly than the process of extracting these features using hand-coding, which is usually the case with traditional feature extraction methods like GEOBIA. Instead of handcrafting a set of rules and algorithms to extract features from raw data, deep learning involves learning these features automatically during the training process.
To enable computer systems to identify a variety of features gathered by multiple sources, it must be fed examples that will help it identify and learn. For example, creating samples of different types of buildings, factories, warehouses, sheds, restaurants, etc., can show the computer how to identify each polygon and recognize every type of structure. This way the computer learns what is a building and what is not a building, as well as what is a road, river, forest, etc. The predictive ability of AI enables it to then identify a building and quantify its measurement.
It has become clear, however, that the biggest challenge to deep learning for remote sensing is the availability of high-quality, timely, and labeled data needed to drive the training process. For supervised learning, data is labeled and represents a specific feature, like a building, driveway, or parking lot. This labeled data is used as training data. The geospatial specialist labels supervised classification data into multiple categories and the computer generates the statistical compilation for these features.
Once a model is in place and it can identify the characteristics in that region or topography, the computer can use it repeatedly to extract data from that region. And with each project, the computer gets smarter and more capable to handle the next project.
Case Study: Franklin County, Ohio
In 2020, Woolpert used deep learning for a project contracted with Franklin County (Ohio) Auditor’s Office. The firm was hired to produce a comprehensive building outline map throughout the county and the capital city of Columbus.
The Franklin County Auditor’s GIS manager Matt Shade said the building data is used to build an accurate base map for the county. He said the outlines are compared with the building area on file to detect changes in structures, capturing anything that may have been missed using other methods.
“The primary reason for our office to take on this project was to use it as one of many inputs to provide fair, equitable, and accurate assessments,” Shade said. “We realize that it is used in a variety of ways beyond our office and having it accessible is important to us. Some of the community uses include urban planning, preliminary engineering, and economic development.”
Woolpert, which is headquartered in Dayton, has collected and processed remote-sensing data for multiple building outline, impervious surface, and related feature extraction projects throughout the United States.
“Building extraction is an aspect of deep learning that has made significant advances in support of remote sensing, and we’re actually using it for real problems,” Stevens said. “Every year we have multiple building outline projects, and these projects are all being used to help train computer systems to make all subsequent projects process more efficiently and more accurate.”
This previously collected data was ingested into the computer to create a model. This enabled the computer to identify and extract the features specific to this region and this project. A process that would have taken six weeks was reduced to 10 days, and the quality of the deliverable was vastly improved.
“Once the model is ready, it’s similar to a push-button operation and out comes the project building outlines that are 70 percent ready to go, with very minimal human intervention,” Stevens said. “The standard protocol for this project would have required a lot of time up front designing and assigning algorithms, followed by multiple iterations of that data. And even then, the result would be only 40 percent usable.”
Shade noted that this is a large project for the county and having a quality product in a short amount of time was a great benefit. “The longer the processing time, the more the base data gets out of date,” he said. “This project creates a baseline for our building outline data, with consistently applied rules throughout the entire county.”
The knowledge the computer has gained from this Franklin County data is already being employed to benefit subsequent projects.
Conclusion
The science-based analytics and efficiency realized by using deep-learning techniques are helping to address an expanding need for remote-sensing data. It is equipping clients with the knowledge needed to make accurate and timely decisions and enabling the geospatial scientists and specialists to devote increasing attention to innovative applications.
“We can do more of what we haven’t done before,” Woolpert solutions scientist Matthew Hutchinson said. “Advances like this are providing tools that enable us to ramp up production. For example, we are able to perform cheatgrass mapping at wide scale because we are working with the folks in Wyoming to collect data that we can feed to the computer to show it what cheatgrass looks like. Then we can match that data with lidar from our Leica Geosystems TerrainMapper, one of our linear-mode aerial lidar sensors, and can put together to expand that to map characteristics to the data.”
New and improved components will continue to develop and improve functionality. These will include the refinement of feature classifiers, which help a geospatial specialist decide which feature he or she wants to classify, and the overall movement of these processes to the cloud.
“For our purposes, we want to move our training pipeline from on-premises to the cloud environment, so we will be able to use this model at our office in South Africa and by those in the field around the world,” Hutchinson said. “We also want to democratize it and share it with our bathymetric teams and others throughout the firm who see value in this kind of capability.”
The biggest challenge to deep learning is the need for label data to train the computer to identify and extract features that match the needs of each project. This need gives veteran geospatial firms that are willing to invest in new technologies a distinct advantage.
“Woolpert is fortunate that it has more than 50 years of experience generating mapping data, not only for our geospatial pursuits but for our architecture and engineering groups as well,” Stevens said. “However, a distinct benefit to AI and deep learning for any firm is that it is agnostic. It’s not designed for one sector or profession, and it adjusts to geospatial data as well as it does to CAD. It’s being used for everything from autonomous vehicles to agriculture to health care—and we are still just at the dawn of what’s possible.”