
How AI is going mainstream in the infrastructure industry.
For years, humans have recognized images better than computers have. Our error rate has been steady at 5% while computer algorithms were at 30%. However, with the rise of computer vision and deep learning, the gap between humans and computers has slowly closed. Within the last two years, researchers have seen computer algorithms show an error rate of less than 5%, surpassing humans. These advancements bring significant potential to many different industries.
In the infrastructure industry, users have applied reality modeling in countless projects to improve all workflows. A 3D model can provide real-world, digital context with the information that stakeholders need to design, construct, and operate assets, helping improve decision-making. However, there are still ways to maximize the value of reality modeling.
Within the last five years, AI (or artificial intelligence) has gone mainstream. It no longer relates to just the technology industry; it is being adapted and applied to increase its value across all sectors, such as customer service, business intelligence, marketing and sales, and even the legal service. The infrastructure industry needs to keep up.

Object classification of trees in a 3D reality mesh of a roadway.
Understanding the Language
Before we can talk about the benefits of reality modeling, we need to agree on a few terms. Often, people confuse AI, machine learning, and deep learning. The terms might be interconnected, but they have very different meanings.
“AI is just the generic terminology for doing something smart with the computer,” explains Bentley’s Renaud Keriven, distinguished engineer, software development, reality modeling product development. “Every time a computer is doing some kind of reasoning, it’s AI.”
Keriven explains that AI is not only computing results or processing data, but also having the computer reason with the data. For example, programming a computer to speak is not AI. However, if you were to program the computer to give speech and understand its meaning, that process would be AI.
Zheng Wu, Bentley fellow, defines AI as a broad topic of computer science: “AI itself contains many subjects, including optimization, expert systems, robotics, language processing, computer vision, and machine learning.”
Machine learning, another important term, falls under the umbrella of AI. Machine learning is the process of getting a computer to learn by itself. “Once the computer is programmed,” says Keriven, “it is capable of machine learning. You just have to show it some examples—for instance, images of trees and cars—and it learns the difference between trees and cars by itself.” If you have a smartphone, chances are that you are seeing machine learning technology. Most smartphone cameras can identify faces and focus in on them.
Deep learning, a subdomain of machine learning, is another step further. With this technology, researchers are trying to mimic the human brain by adding multiple layers of artificial neurons. “It is this idea from the 70s where people tried to model and program neurons, and then connect neurons together and let them evolve naturally to learn something,” Keriven explains. Unfortunately, the technology back then was too slow and it didn’t work.
In recent years, however, deep learning has seen great advancements. “Around 2006, there was a breakthrough in how the neuro-network can be trained where there are more layers than the classic artificial neuro-network,” Wu explains. “The researchers in universities can train very large deep learning neuro-network models to do all kinds of stuff: image and feature recognition, object detection, language processing, and much more.”
Teaching Computers to “See”
Machine and deep learning make it possible for computer vision and image recognition to identify problems with projects or individual pieces of equipment before they happen. Computer vision is the broad subject, with image recognition as a subdomain. Computer vision allows the machine to detect specific types of objects. The goal is to teach the computer to see like humans.
“To teach a computer to see stuff, we have to use a semantic model, a mathematical algorithm, to detect features and track those features. That is the challenging part,” says Wu. He adds that over the last decade, especially in the last few years, there have been great advancements in developing those feature recognition algorithms. The reason is because of the advancements in deep learning.
“Deep learning and computer vision are closely related to each other,” he explains. “You can say that deep learning is part of computer vision or that computer vision uses deep learning techniques to teach the machine to see stuff.” He and his fellow researchers are applying classic computer vision techniques together with deep learning to improve efficiency and effectiveness and overcome challenges.
When teaching a computer to see like a human, image recognition is key. It is the process of identifying and detecting an object or a feature in a digital image or video. There are three steps: classification, detection, and segmentation.
Classification involves asking the computer to identify a single category in an image. Keriven explains, “You classify your mesh or your 3D model between different categories. You have the computer ask: Is this a tree? Is this a car? Is this a human?” Wu also explains that classification does not have to be just images. “Deep learning and computer vision can also apply to point cloud data.”
Detection is a bit more focused. This time, there is an image and you want the computer to detect where objects are in the image. “It’s just like drawing boxes in your image so every box is around one object. You do the same in 3D when you have a reality mesh,” says Keriven.
Segmentation is one step further, as Keriven explains. “Segmenting is just like drawing around the exact shape of the object, either in 2D or 3D. For instance, when identifying telecom towers and antennas, detecting is enough. We just want to know and find boxes in our 3D reality mesh where the antennas are. Segmenting could be useful if you want to detect the ground in a mesh or in an image. You just identify the parts of your mesh that are the ground. For each part of the mesh, you say, ‘This is ground’ or ‘This is not ground.’”
Recently, Bentley has used this type of computer vision to detect faults in concrete. Many organizations use the technology to identify cracks, including their shape and depth.

A 3D reality mesh of an interior brick wall.

Automatic crack detection in the wall.
“To put this in perspective,” says Wu, “if we try to detect a crack in an image, we can detect the cracks with a bounding box. You can see what is detected in the bounding box. That doesn’t tell you exactly what that crack or that defect looks like. Researchers don’t have information on the shape or width of that crack. Now, with a 3D reality mesh, we will not only detect that crack with a bounding box, we’ll segment that crack, that defect, in the exact shape, size, and scale of that crack.”
Wu and his team can build a 3D model using images with the detected cracks and run statistics to determine its length, width, and other pieces of critical information for the engineers.
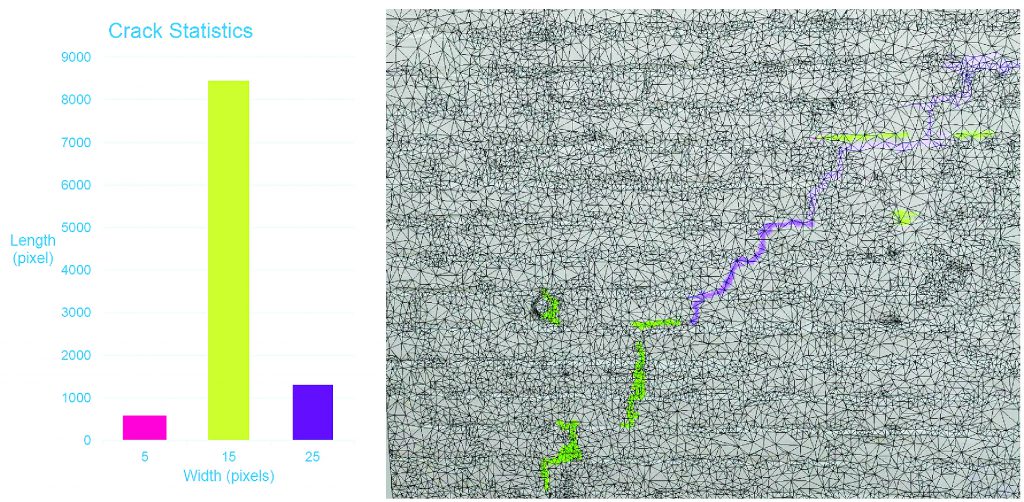
The analysis of automatic crack detection data.
Visualizing Advantages
One exciting feature about image recognition is the ability to train the multi-layered artificial neural network with thousands of images to recognize an object. Once the model is trained, it can be used to recognize the similar object in a new image.
With this feature, researchers can build schematic 3D models. This model would be classified so engineers know the details of what they are seeing in the model while maintaining the high-quality color and texture of a regular 3D model. This feature is incredibly helpful for infrastructure inspections.
Recently, Wu and his team conducted two projects that feature this kind of model. The first was right at Bentley Systems’ headquarters in Exton, Pennsylvania. The team collected a dataset of their Exton campus and sent the data to Wu and his team.
“We analyzed the data and classified the features in the image to separate the pavement from other features. We can classify the trees, the vegetation, the buildings. So, hopefully, that classification will help us to build a classified semantic 3D mesh model.”
Another similar project was with CH2M Fairhurst in Europe. Their team provided a dataset for Wu to classify the trees on both sides of the road in preparation for a highway upgrade. “CH2M needed a 3D model without trees on both sides of the roads to generate a new road design,” explains Wu. “To remove the trees, you first need to know where the trees are, and then classify them.” Normally, the process would be to go into the program and manually remove all the trees. This time-consuming process was eliminated using reality modeling.
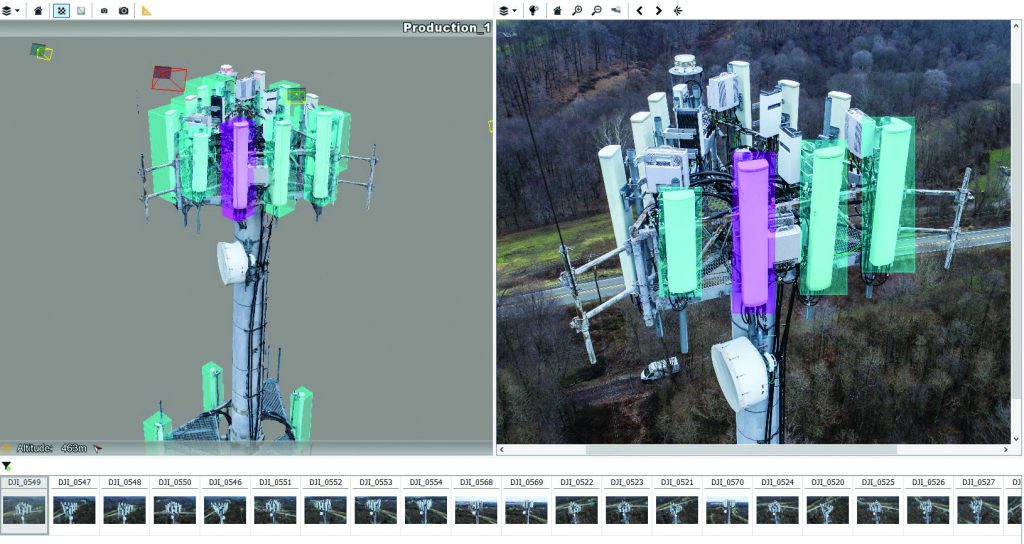
Automatic detection of telecommunications tower antennas in a 3D reality mesh, generated from images taken from a drone.
The Endless Possibilities
Both Wu and Keriven believe there are many ways that the infrastructure industry can apply computer vision, or AI in general, to keep the industry moving forward. One place that they see progress is with Bentley’s ContextCapture and the application’s ability to classify images in reality meshes.
“With ContextCapture, we’ll soon use neuro-networks that have already learned a lot of things from many different images,” says Keriven. “We can take this brain and teach it how to detect objects that it has never seen before. If users want to detect their own object, we’ll be able to provide a way to select this object in their images so that ContextCapture will learn these objects and detect them mathematically in the future.” The team hopes to have a beta version of this new capability soon.
Another way that AI can help the industry is by using it to advance reality-modeling applications themselves. Keriven believes that AI can help improve ContextCapture, both the technology and the user’s experience.
“If you understand what kind of object you are facing, of course you will be able to get better 3D meshes and models. If you know that you are reconstructing a road, building, communications tower, or whatever, you can adapt what you are doing to find a better road, a better building, a better whatever. You can put AI everywhere.”
Progress is also being made in how this technology can be leveraged to maximize the value of reality modeling and improve productivity. By creating 3D models, users will have better visibility into their project’s progress and end-goals.
“I’m nearly confident that we are in a good position to achieve a 3D semantic model with our research and our product team,” says Wu. “Hopefully, in the very near future, we will enable our users to classify all their visual data. They can construct the semantic 3D models, and have the 3D models not just for visualization but for infrastructure engineering, design, maintenance, and inspection.”
Using reality-modeling applications to create the models will accelerate the design process while keeping everyone informed of changes. But, moving forward, Wu hopes to conduct more research into detecting different defects in infrastructure assets. Currently, he and his team are working with three organizations in Southeast Asia to detect various assets, including mass rapid transit rail tracks, cranes in major ports, and underground tunnels.
“If we just take those three examples, you can imagine that there are many other things—infrastructures and built environments—where we can apply those techniques and expand them,” he says.
Reality modeling using AI can be applied to many different areas of the infrastructure industry and help with all stages of an asset’s lifecycle. As the technology continues to advance, it becomes clear that there is no limit to what reality modeling can do.
Image at top: This 3D reality mesh of a business park allows for object classification of trees.